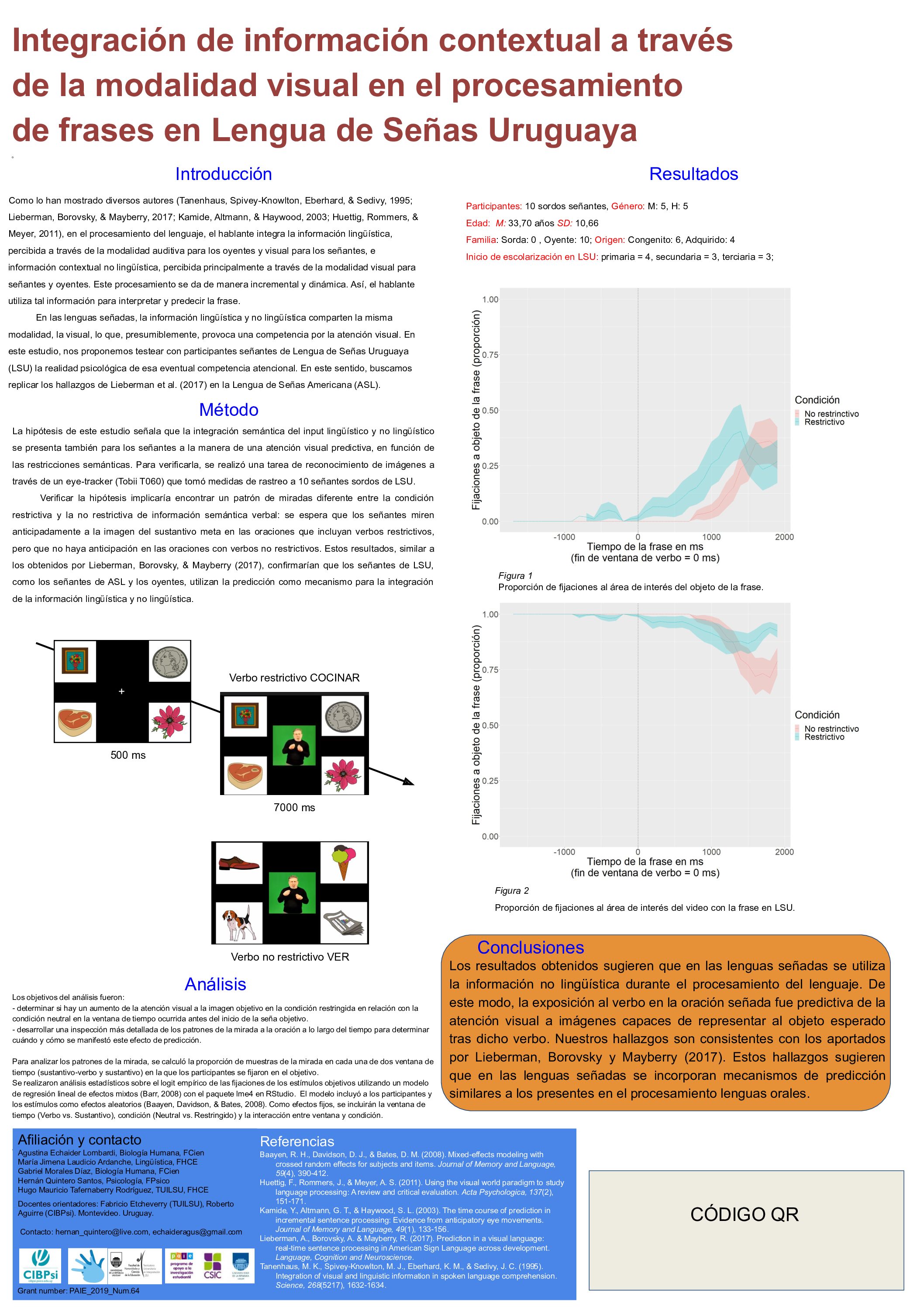
En las lenguas señadas, la información lingüística y no lingüística comparten la misma modalidad, la visual, lo que, presumiblemente, provoca una competencia por la atención visual. En este estudio nos propusimos testear con participantes señantes de Lengua de Señas Uruguaya (LSU) la realidad psicológica de esa eventual competencia atencional. La hipótesis de este estudio señaló que la referida integración semántica del input lingüístico y no lingüístico se presenta también para los señantes a la manera de una atención visual predictiva, en función de las restricciones semánticas. Para verificarla, se realizó una tarea de reconocimiento de imágenes en la que participaron 10 señantes sordos de LSU. En este caso se tomarán medidas oculares a través de un eye-tracker para testear las hipótesis del estudio. Si bien los resultados no son concluyentes, apuntan a que, efectivamente, hay, para la población señante-sorda, una integración de la información lingüística y no lingüística al momento de predecir el significado de las frases. Esto, a pesar de la situación de competencia atencional dada por la modalidad visual de la lengua.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}